Lessons Learned from Creating a Simple Audio Player
A few months ago, I decided that I was going to develop my own “music player” software. There was a time when music player software was pretty ubiquitous, with many people opening up iTunes or Windows Media Player when they wanted to listen to their music on their computer. However, with streaming becoming the preferred mode of music consumption for most listeners, these apps are far less popular today.

That said, I am still one of those luddites who prefers to own their music, perhaps an artifact from my time as a radio DJ. At the time of writing, my music library contains 6,274 songs, spread across 564 albums, and featuring 343 artists. So I need to have a music player app on my computer that I can use to listen to all that music, and the past few years I’ve been having trouble finding one that I like.
I never much cared for the user experience of Windows Media Player, and iTunes was too slow and never ran well on my Windows machine. On my phone I used the VLC Media Player app until very recently, but for whatever reason, I couldn’t get used to using VLC on my PC. For the past few years, my music player of choice has been Dopamine, a simple and open-source music player app. Dopamine is a wonderful app and contains way more features than I could ever hope to implement in my own app, but still had a couple of pain points: library scanning time and memory usage.

ChowTunes
So last August, I started developing my own music player called “ChowTunes”. ChowTunes is not meant to be “serious” software, in the sense that I don’t really see anyone other than myself using it, and I don’t really care about making sure it’s compatible with different operating systems, audio drivers, etc. At the moment, ChowTunes is very feature-sparse: you can browse your music library, add songs to a “play queue”, and then control the playback “transport” (i.e. play, pause, seek, etc). Probably the most sophisticated feature implemented so far has been a simple “search” feature, to search for albums/artists that match some input query. While Dopamine and most other music players have many more capabilities (e.g. making playlists), I don’t really feel that I need much more, at least for my own personal listening experience.

Disclaimer
In the following sections I’m going to discuss some performance comparisons between ChowTunes and Dopamine. Please keep in mind that Dopamine is a much more fully-featured app than ChowTunes, and that I was testing with Dopamine 3, which is still in pre-release (I was testing with version 3.0.0-preview.25). I’ll be a bit more specific about the performance differences in each area of comparison, but I really don’t want to come across as though I’m putting down the Dopamine developers, especially since Dopamine is far more performant than most other music player apps that I’ve tried.
Library Scanning
When you first open up Dopamine, ChowTunes, or most any other music player app, you will be asked to select a folder on your computer that contains your music library. From there, the app will walk through the provided folder and “scan” every available audio file, to obtain information including the song title, artist, album, runtime, etc.
The first time Dopamine scans my music library, it takes ~3 minutes to scan all the song files, followed by another ~2 minutes to retrieve album artwork. Dopamine has a much higher success rate than ChowTunes for retrieving album artwork, so I’m going to assume they’re doing something useful with that extra 2 minutes. Once Dopamine has scanned the library once, I’m guessing it stores the scanning results somewhere on disk, since any scans after the first one take significantly less time. However, when I add a new album to my music library, I can expect another 10–20 second library scanning wait the next time I open Dopamine.
With ChowTunes, scanning my entire library takes ~500 milliseconds, which feels nearly instantaneous. I could have also chosen to cache the results of the scanning process, but then I would have also needed to implement some way of figuring out if any files in the library needed re-scanning, which would have been more complicated and maybe not much faster than just re-scanning the whole library every time.
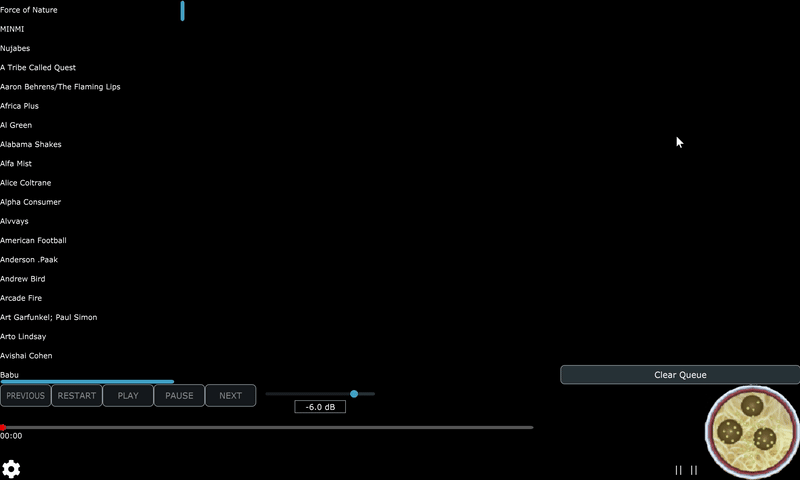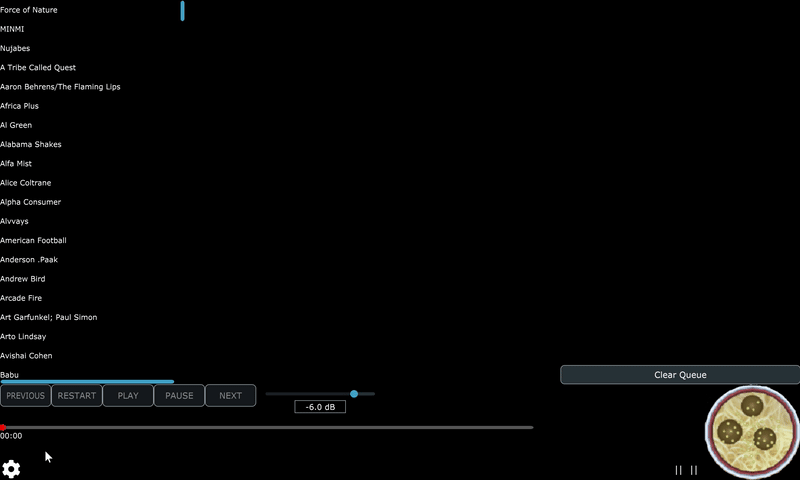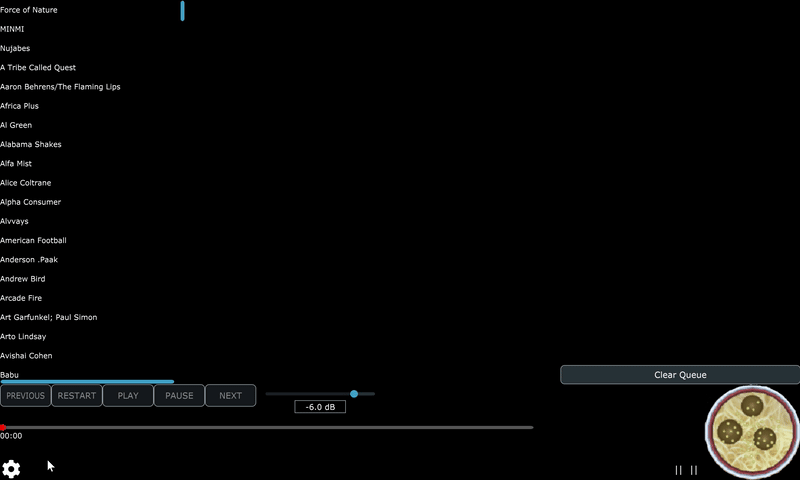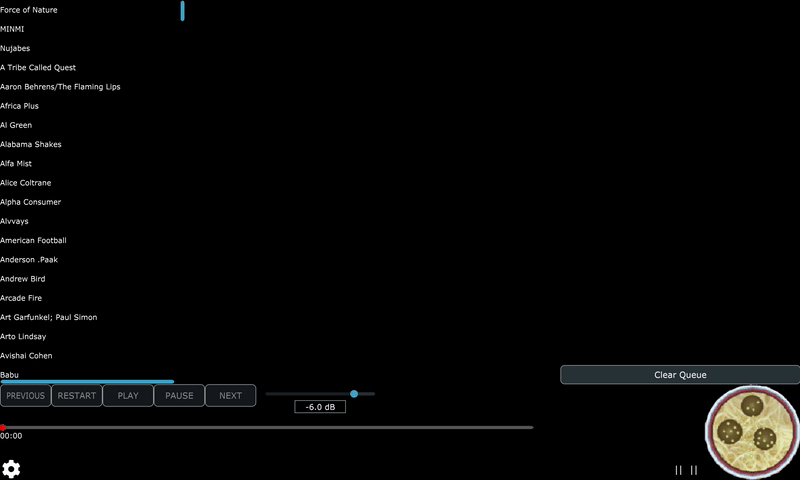
At the moment, the biggest “bottlenecks” in the library scanning process are coming from TagLib dependency that I’m using to obtain metadata from the audio files in the library folder. There may be some ways to improve my usage of TagLib, or to roll my own replacement that sacrifices some functionality for superior performance, but for now I’m happy enough with the speed of the library scanning process.
Memory Usage
One of my other issues with Dopamine was memory usage. When the app was idle (i.e. not playing any music), Dopamine was using ~200 MB of RAM, a number that increased to ~300 MB when the app was playing back some music. While that number was better than many of the other music player apps I’ve tried, I still found it rather high for my tastes, especially on my old Dell laptop with only 8 GB of RAM.
At the moment ChowTunes uses ~25 MB of RAM when idle and ~150 MB when playing music. That said, I haven’t spent a ton of time yet optimizing for memory usage, so I imagine those numbers could be reduced with a bit more effort. In particular, when playing back a file, ChowTunes loads the whole file into memory rather than “streaming” it from the disk in chunks, which is probably a large contributing factor towards the 150 MB.

At this point, it’s probably worth mentioning that Dopamine is written using the Electron JavaScript framework, a framework known for being rather memory-heavy. ChowTunes is written in native C++, using the JUCE framework for graphics. I chose JUCE because it’s the framework that I know best (not necessarily the most efficient), however, I have considered using a different graphics framework for ChowTunes just to see what else is out there.
But… How?
A natural question to ask about the above points is how ChowTunes is able to achieve its current level of efficiency. An easy answer would be “well it’s written in C++, so of course it’s fast,” but I’ve seen enough slow and inefficient C++ software to know that there’s more to making a performant app than just your choice of programming language. Here I’ll discuss some of the programming techniques that have helped make ChowTunes both exceedingly efficient and (in my opinion) easier to program.
Memory Arenas
Memory arenas are a wonderful programming technique for managing memory with a common “lifetime”. For a more comprehensive discussion of memory arenas in general, please check out Ryan Fleury’s blog on the subject. For now I’ll just note that both constructing and visualizing the music library is a natural task for memory arenas, since all the data in the library has the same lifetime.
For example, think about how we might want to store song names in the library. A standard C++ approach would be to store each song name in a std::string, each of which might incur it’s own individual memory allocation (assuming most song names are long enough that small-string optimization doesn’t help). However, we know that all of the song names will have the same lifetime, which is the same as the lifetime of the library.
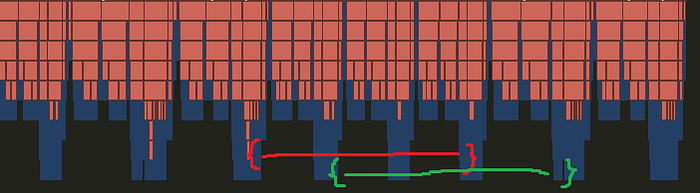
So a more optimal (and in my opinion, simpler) approach is to allocate all the memory needed for song name strings in a memory arena. Then whenever we need scan a new song, the song name, artist, and album name can all be constructed as string “views” using memory from the arena (which will almost always be faster than getting it from the heap). Finally, we never need to worry about the lifetimes of these strings, since we can “reclaim” all of the memory in the arena when we no longer need the library (e.g. when re-constructing the library from a different folder). As a bonus, all the memory in the arena is contiguous, meaning that reading or writing to data stored in the arena is typically cache-friendly.
Thread Pooling
Another way that I’ve tried to optimize the library scanning process is by splitting up the work over multiple threads. For a small music library (e.g. ~300 songs) scanning the library on a single thread is often faster than using multiple threads, but as the library size grows, the more important multi-threading becomes. Rather than using the multi-threading APIs available in the C++ standard library, ChowTunes uses Barak Shoshany’s thread_pool implementation.
#include "BS_thread_pool.hpp"
BS::thread_pool thread_pool {};
for (auto const& dir_entry : std::filesystem::recursive_directory_iterator (path))
{
const auto extension = dir_entry.path().extension();
if (dir_entry.is_regular_file())
{
tag_results->push_back (thread_pool.submit (
[file_path = dir_entry.path()]() -> Tag_Result
{
TagLib::FileRef file { file_path.c_str() };
return {
.file = file,
.tag = file.tag(),
.file_path = file_path,
.artwork_path = artwork_file,
};
}));
}
}Keep It Simple
It’s not the code you write, it’s the code you don’t write.
- probably Miles Davis if he ever wrote software
When I was taught about software design, I was taught to avoid optimizing my code too early in development process, so as to avoid the dangers of “premature optimization”. However, as I’ve learned more about software development, I’ve seen more and more of what I would call “premature pessimization”, where the developers have chosen data structures, code abstractions, and program flow mechanisms that make it difficult to achieve optimal performance even after several optimization passes. In these cases, the developers either have to live with their less performant software, or re-write much of their code with performance as a more immediate concern.
So when writing ChowTunes, my goal was to do as little pessimization as possible. In practice, this meant asking myself “what is the problem I’m trying to solve?” and then writing code to directly solve the problem, without going through any additional complexity or abstractions. While this often led to some code that seemed “bad” in the short term (often quite repetitive and verbose), it cleaned up quite nicely after a little bit of refactoring (which still seems to be necessary even when starting with more abstractions or high-level designs).
Unlike with the memory arena and thread pool, it’s impossible to measure the performance boost that I may or may not have achieved by programming with this simpler philosophy. However, I do feel that the ChowTunes codebase is a lot simpler than the codebases I typically work with, and with a bit more time and effort, I could probably achieve even better performance without needing any larger re-structuring or re-writing (except in relation to third-party dependencies).
Wrapping Up
As I mentioned earlier, ChowTunes is not meant to be a serious piece of software used by lots of people. The idea is just to create something that I can happily use myself, and to have a fun and educational time while doing so. That said, if you’d like to try out ChowTunes, or have some ideas for improving it, feel free to have a look at the project’s GitHub repository.
To wrap up, I’d like to paraphrase some the lessons that I’ve learned while developing ChowTunes:
- Keep your code simple. Solve the problem in front of you first, and don’t bother with abstractions until you’re sure that they will make you life simpler, and won’t ruin performance.
- Memory arenas are great! They help to simplify a lot of lifetime management problems, while also making it easier to write fast, cache-friendly code.
- Incremental problems are often hard (e.g. incrementally scanning the music library), but can sometimes be avoided by just doing the whole task fast enough to obviate the need for an incremental solution.
Onward!